
The Moat is Gone: DeepSeek just matched Gemini & GPT-5
Plus: OpenAI declares "Code Red," Anthropic’s $50B industrial pivot, and the 42-cent model challenging US dominance.

🎵 Podcast
Don’t feel like reading? Listen to it instead.
🖼️ This week’s image aesthetic (Flux 2 Pro): Rembrandt-Style Oil Painting
📰 Latest News
Chinese lab DeepSeek matches Gemini 3.0 Pro and claims Maths Olympiad gold with new ‘Speciale’ model.

DeepSeek has effectively erased the performance gap between open-source and proprietary AI with the release of DeepSeek-V3.2 and the advanced DeepSeek-V3.2-Speciale.
The standard V3.2 model is free and matches the capabilities of OpenAI’s GPT-5, while the API-only Speciale variant rivals Google’s Gemini 3.0 Pro, achieving gold medals in the 2025 International Math Olympiad. These milestones are driven by the DeepSeek Sparse Attention (DSA) mechanism, which reduces memory usage by 70%, boosts speed by 3.5 times, and slashes inference costs by over 60%.
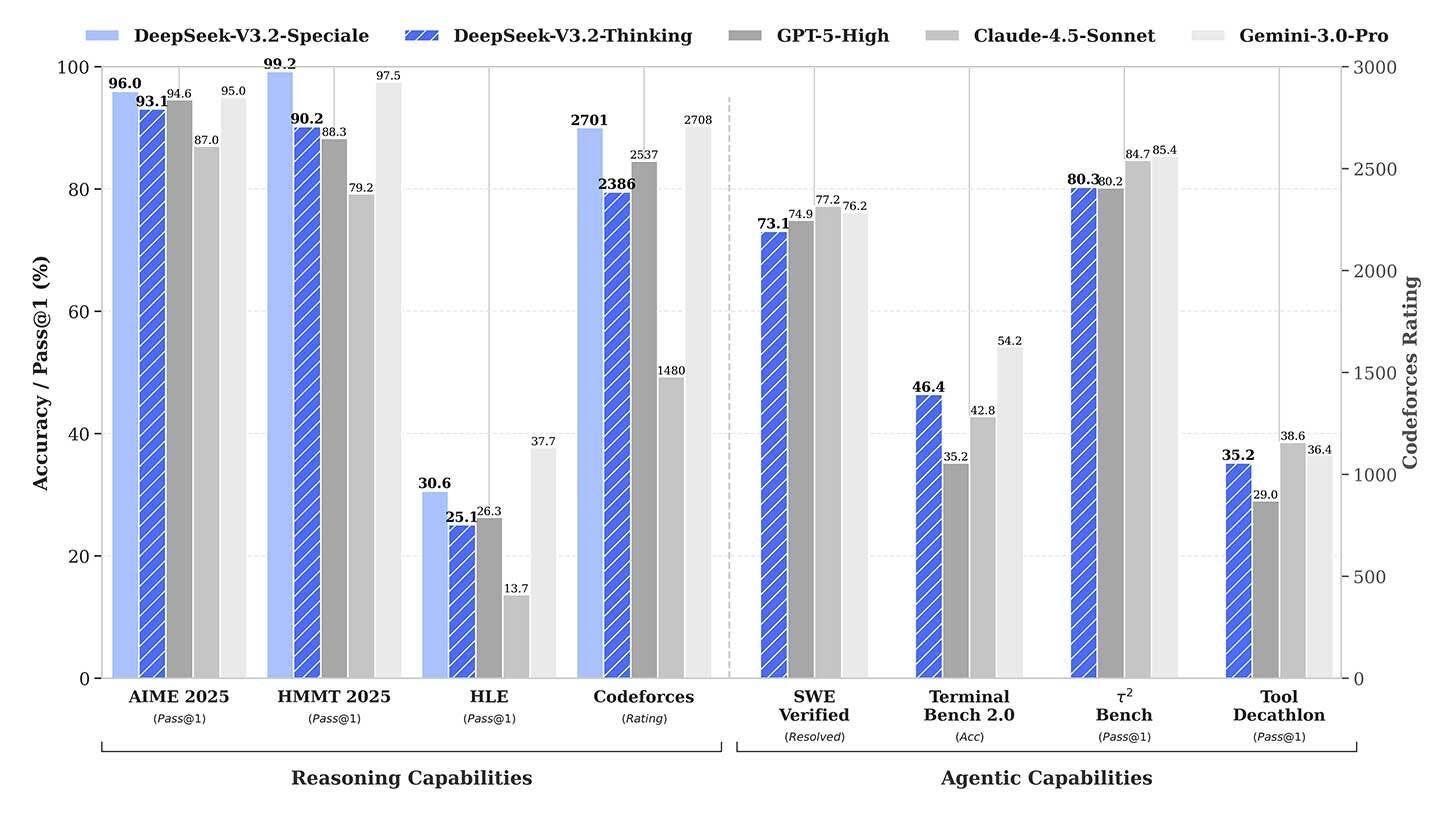
Why it matters:
This release represents a fundamental challenge to US tech dominance. By proving that a Chinese lab can reach the frontier of AI capabilities, DeepSeek has shattered the assumption that state-of-the-art performance requires the massive budgets of closed ecosystems. With the Speciale model priced at a disruptive 42 cents per million tokens, high-level intelligence is effectively commoditised. This economic shift allows developers to integrate advanced, long-context reasoning into everyday consumer applications—deployments that were previously too expensive for anyone but large enterprises.
Altman issues ‘Code Red’: OpenAI halts consumer expansion to prioritise the ‘Garlic’ reasoning model.

OpenAI CEO Sam Altman has issued a “code red” directive, halting development on peripheral features—including advertising, shopping, and a new assistant named “Pulse”—to refocus the entire company on ChatGPT’s core performance.
The mandate prioritises speed, reliability, and personalisation over expansion. Resources are being aggressively diverted to a new large language model codenamed “Garlic”, which insiders report is performing exceptionally well on coding and reasoning tasks. Slated to potentially launch as GPT-5.2 or GPT-5.5, “Garlic” represents a push to stabilise and upgrade the underlying intelligence of the platform rather than adding consumer “super-app” features.
Why it matters:
This strategic U-turn signals that OpenAI recognises its “moat” is shrinking. By sacrificing immediate revenue avenues (ads) to perfect the core experience, the company is betting that superior model competence is the only viable defence against rapidly advancing rivals like Gemini 3. For developers and enterprise users, the focus on “Garlic’s” reasoning capabilities suggests a return to building a robust infrastructure tool, moving away from the distracted, “jack-of-all-trades” product development that has characterised recent months.
Harmonic’s Aristotle AI solves the 30-year-old Erdős Problem #124 using self-verifying code.

Harmonic’s Aristotle AI has independently solved a variant of the 30-year-old Erdős Problem #124, demonstrating a new way for computers to handle complex mathematics.
Instead of trying to calculate the answer using complex code from the start, Aristotle used plain English to reason through the problem step-by-step—much like a human mathematician drafting ideas. This “thinking” phase took just 6 hours to find the solution. Crucially, the AI then translated its answer into Lean, a strict mathematical programming language, which verified the proof was 100% correct in only 1 minute.
Why it matters:
This approach solves the “hallucination” problem that plagues tools like ChatGPT, which often sound convincing but make up facts. By combining creative exploration (using everyday language) with rigid computer verification (using code), Harmonic has created a system that is both imaginative enough to solve old problems and rigorous enough to guarantee the answers are true. This paves the way for AI to autonomously clear scientific blockers that have stumped researchers for decades.
Anthropic pivots to an ‘industrial phase’, securing new data centres in Texas to train models beyond Claude 3.5.

Anthropic’s potential IPO is less about the stock market and more about amassing a war chest to physically build the next generation of AI intelligence.
Anthropic is preparing for a public listing that could value the company at over $300 billion, alongside securing a massive $15 billion combined investment from Microsoft and Nvidia. However, the most critical detail is the company’s simultaneous announcement of a $50 billion infrastructure build-out, including new custom data centres in Texas and New York. This capital injection transforms Anthropic from a research lab into an industrial-scale operator, securing the hardware necessary to train frontier models that vastly exceed the capabilities of the current Claude 3.5 series.
Why it matters:
This move signals the beginning of the “industrial phase” of AI, where progress is determined by physical infrastructure rather than just code. The $50 billion allocated for data centres and the direct backing of Nvidia ensures Anthropic has the computational sovereignty to train models orders of magnitude larger than today’s standards. For the industry, this guarantees a genuine “two-horse race” against OpenAI, preventing a monopoly on super-intelligence. It means Anthropic will possess the brute-force processing power required to solve complex scientific and reasoning problems that are currently impossible, effectively securing a high-performance alternative for the global enterprise market.
Runway’s ‘David’ beats the Goliaths: Gen-4.5 tops global blind tests.

Runway has released Gen-4.5, a video generation model that topped industry leaderboards under the blind alias “Whisper Thunder,” beating billion-dollar competitors to the number one spot.
Internally codenamed “David” to signify a victory over the industry’s Goliaths, Gen-4.5 achieves a breakthrough not just in visual fidelity, but in physical logic. Unlike previous models that often hallucinated motion, Gen-4.5 accurately simulates complex fluid dynamics, fabric weight, and human micro-expressions. Runway claims the outputs are now “indistinguishable” from real footage. By excelling in blind testing before its official branding was even revealed, the model proved that a focused startup could outperform the massive compute resources of major tech incumbents in creating hyper-realistic video.
Why it matters:
The success of Gen-4.5 suggests that the future of generative media is shifting from “animation” to “simulation.” The model isn’t merely predicting the next pixel; it appears to be building an internal understanding of physical laws—how water splashes or how hair falls—without being explicitly programmed to do so. This implies that the barrier to cinematic creation is no longer budget or equipment, but imagination. Furthermore, the “David vs. Goliath” victory proves that innovation in AI is not solely a function of massive scale, signaling that nimble, specialised labs can still outmanoeuvre entrenched tech monopolies in the race to simulate reality.
Last weeks newsletter:
